Executive Summary: Data Backup and High Availability by Peer Software
Data backup and high availability are two sides of the same coin. One does not necessarily replace the other. Data security is predicated on redundancy. Multiple safeguards can help ensure your operational solvency.
Peer Software’s Global File Service can help your team simplify and manage unstructured data backup, high availability, and automatic failover across multiple geographic locations as well as mixed on-premises and cloud storage environments.
If your IT infrastructure goes down the cost of the outage can be catastrophic if service and functionality are not restored quickly. According to Statista, system outages cost business owners an average of $300,000-$400,000 per hour. That’s why it is essential to develop systems of redundancy to help safeguard your company’s critical data in the event of an unforeseen interruption.
Peer Software is proud to present a four-part web series on the topic of data protection and data availability. The web series will include information on the following topics:
- Backup vs. high availability
- Evolving from backup to high availability to always-on
- The requirements of building an always-on enterprise
- The evolution from data backup to intelligent data availability
Today we’ll focus on the topic of data backup versus high availability, two different, yet equally critical pieces of the data protection puzzle.
What Is Backup?
Before diving into an all out comparison between the two, it’s useful to define each method in order to further scrutinize how the two systems work together.
Data is your company’s lifeblood. From client and vendor information, to accounting functions, to inventory management, no matter what industry you serve, you collect a massive amount of data in the course of your operations. Every business function imaginable is cataloged on your company’s server. But what happens if that server becomes inoperable? Without some form of data backup the impact to your business could be deadly.
To safeguard your business-critical information, you need data redundancy, i.e. copies of your essential data that’s stored in multiple locations. Data backup is the practice of copying your existing dataset to another location for safety purposes. While there are many ways to go about backing up your data, at bare minimum your company should employ a second server that periodically makes a historical log of your primary server’s content. In reality, however, most companies backup their information to multiple locations like additional servers paired with a cloud-based copy.
Frequency is of the utmost importance when it comes to employing data backup. With a typical configuration, the secondary location(s) would record anywhere from once a day, to once every few hours. The configuration you choose will depend on key metrics including:
- Maximum Acceptable Outage (MAO)
- Recovery Point Objective (RPO)
- Recovery Time Objective (RTO)
Together these measurements paint a picture of your company’s risk tolerance as far as data loss and downtime are concerned. MAO refers to the greatest amount of time your business can afford a system outage. RTO is the time between the initial outage and system restoration. RPO refers to the amount of data or information that’s lost in the interim.
Backup Alone is Insufficient
Backing up your company’s data is crucial, but data backup alone is not enough to minimize business disruptions and to ensure business continuity. While copies of data secure your company from permanent loss or damage to business critical files, they are practically useless until they are restored onto infrastructure and validated for integrity to get the business back up and running again.
During this restoration process, the duration of the business disruption is measured against a company’s RTO. The longer the recovery time, the more potentially catastrophic and costly it becomes for the business.
Companies therefore look to High Availability technologies to minimize and potentially eliminate the business disruption that occurs from system outages and natural calamities to ensure continuous IT operations.
What is High Availability?
High availability is a different paradigm which complements data backup procedures. There are three major components of high availability:
- No single point of failure
- Quicker and more reliable rate of crossover
- Increased frequency of backup
Under the high availability (HA) model there is no one point of failure. Each storage location is better leveraged and bears equal importance in your company’s infrastructure chain. HA achieves this kind of parity by updating information at each backup location continuously. When changes are made on your current and primary server those changes are quickly reflected in the backup servers and cloud creating a very, very low RPO with little to no data loss in the case of a service interruption.
If one element of your HA chain does fail, failover is simple, contributing to an extremely low recovery time objective. Let’s say your company employs two physical servers and a cloud-based backup as in our previous example. Under high availability, if your primary server becomes inoperable, a simple “flip of the switch” will transfer operations to your secondary server. Little data loss, little downtime.
If for some reason both physical servers become incapacitated, another flip of the switch transfers operations to a cloud-based virtual machine. You can keep shuffling the active data location between working links in your HA chain until service is restored to your primary data location.
Replication Technologies and Automatic Failover
One of the primary advantages of high availability is the fact that it can be set up so that the “push of the button” is automatic. Should a system element fail, operations will immediately and automatically transfer to the next link in the chain. The service interruption is usually so minimal that the end user might not even notice anything more than a hiccup on their device. This is called automatic failover.
The secret behind high availability’s efficacy lies in the use of replication technologies. We mentioned previously that with HA, backups are performed much more frequently; changes in one data location reflect in the others in a near-continuous fashion. Depending on your resources and your MAO, these updates can occur with almost real-time expedience. Data replication technologies push simultaneous updates to each data storage location on a frequent and incremental basis helping to secure your business-critical systems and information.
Replication Technologies and Automatic Failover
One of the primary advantages of high availability is the fact that it can be set up so that the “push of the button” is automatic. Should a system element fail, operations will immediately and automatically transfer to the next link in the chain. The service interruption is usually so minimal that the end user might not even notice anything more than a hiccup on their device. This is called automatic failover.
The secret behind high availability’s efficacy lies in the use of replication technologies. We mentioned previously that with HA, backups are performed much more frequently; changes in one data location reflect in the others in a near-continuous fashion. Depending on your resources and your MAO, these updates can occur with almost real-time expedience. Data replication technologies push simultaneous updates to each data storage location on a frequent and incremental basis helping to secure your business-critical systems and information.
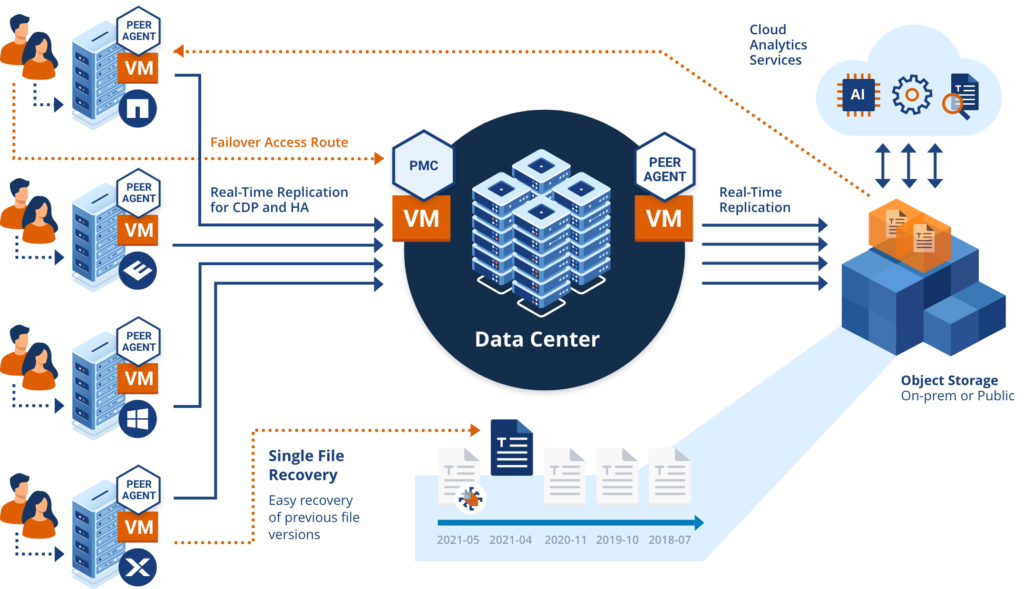
Delivering Backup and High Availability Through PeerGFS
Data backup and high availability are two sides of the same coin. One does not necessarily replace the other. Instead the two methodologies are designed to work in tandem to keep your business operational should the unthinkable happen.
Data security is predicated on redundancy. Multiple safeguards can help ensure your operational solvency. Peer Software’s Global File Service can help your team simplify and manage unstructured data backup, high availability, and automatic failover across multiple geographic locations as well as mixed on-premises and cloud storage environments. For more information on our full line of offerings, please contact us today.
References:
https://www.statista.com/statistics/753938/worldwide-enterprise-server-hourly-downtime-cost/
https://www.carbonite.com/blog/article/2017/05/learn-the-differences-between-high-availability-and-backup
https://www.precisely.com/blog/data-availability/backup-data-high-availability
https://www.techopedia.com/definition/1021/high-availability-ha
https://searchdatabackup.techtarget.com/definition/data-protection

Spencer Allingham
A thirty-year veteran within the IT industry, Spencer has progressed from technical support and e-commerce development through IT systems management, and for ten years, technical pre-sales engineering. Focusing much of that time on the performance and utilization of enterprise storage, Spencer has spoken on these topics at VMworld, European VMUGS and TechUG conferences, as well as at Gartner conferences.
At Peer Software, Spencer assists customers with deployment and configuration of PeerGFS, Peer’s Global File Service for multi-site, multi-platform file synchronization.
- Spencer Allingham#molongui-disabled-link
- Spencer Allingham#molongui-disabled-link
- Spencer Allingham#molongui-disabled-link
- Spencer Allingham#molongui-disabled-link